Best Resources for Understanding Attention and Transformers
If you are like me, an engineer who builds systems but is also curious and wants to understand all the mathematical details behind ML models, you would definitely want to understand the mathematical details of attention in transformers, arguably the most important AI/ML theory in history so far.
At the diagram level, the idea sounds straightforward: tokens look at other tokens and decide what matters, but it is not easy to understand or get the intuition of it from the mathematical perspective.
After going through a number of explanations, these are the resources I would recommend.
1. Attention in Transformers: Concepts and Code in PyTorch
My top recommendation is Attention in Transformers: Concepts and Code in PyTorch from DeepLearning.AI, taught by Josh Starmer from StatQuest.
The reason it works better than most explanations I have seen online is that Josh uses small mock examples to show how embedding values change across the computation. To me, this is really intuitive. You are not only told that attention creates context-aware embeddings; you can follow how the numbers move from token embeddings, to queries/keys/values, to attention scores, to softmax weights, to the weighted sum that becomes the next representation.
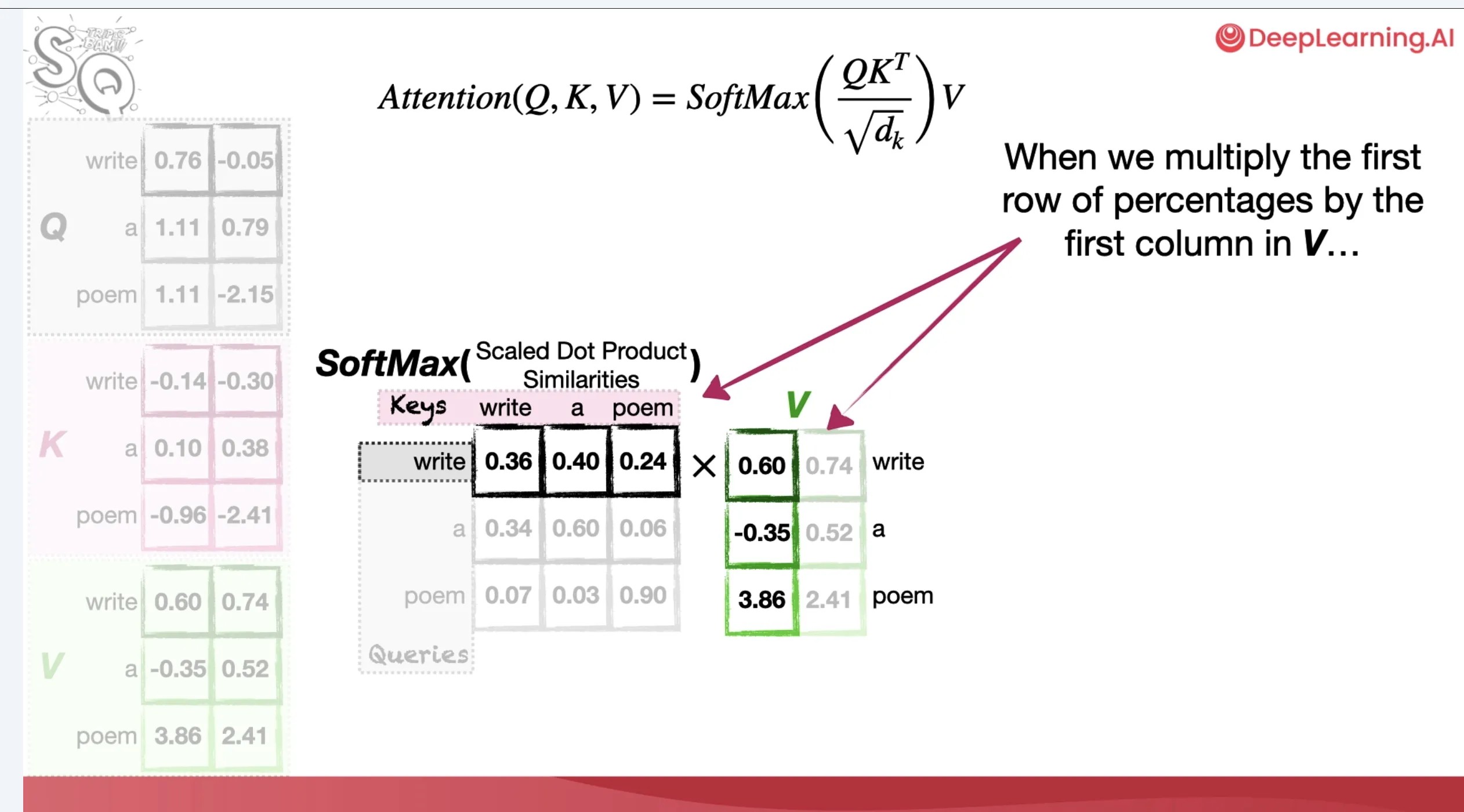
Screenshot from DeepLearning.AI’s Attention in Transformers: Concepts and Code in PyTorch.
That makes the math feel less like notation and more like dataflow.
One caveat: to really understand Josh’s content, you still need some basics in linear algebra, neural networks, and word embeddings. The explanation is beginner-friendly, but it is not magic. It works best if matrix multiplication, learned weights, and embedding vectors are at least familiar ideas.
Josh’s course focuses on demonstrating the mathematical intuition behind the attention mechanism. Attention is a critical part of the transformer, but it is not the full picture of the transformer architecture. For that broader architecture view, I would go next to Jay Alammar.
2. The Illustrated Transformer
Where Josh’s course zooms in on attention, The Illustrated Transformer by Jay Alammar zooms out to the whole architecture. It is the clearest visual walkthrough of the full transformer I have found.
This is the resource for building the high-level map: encoder, decoder, embeddings, positional information, self-attention, feed-forward layers, residual connections, and layer normalization. Once you see where attention sits inside that pipeline, it stops being an isolated formula and becomes one block in a picture you can hold in your head.
Additional Resources for Other Preferences
The Annotated Transformer
The Annotated Transformer is useful if you prefer learning from code and implementation notes. It is more demanding, but helpful once Q, K, V, masking, and multi-head attention are already familiar.
Attention Is All You Need
Attention Is All You Need is worth reading if you want to connect the tutorials back to the source. I would not use it as the first explanation, but it becomes much easier after the concepts have somewhere to land.
Final Note
If I had to compress everything above into one sentence: attention lets each token look at the other tokens, decide which ones matter, and update its representation using that context. The attention scores are the weighting step: they decide how much each neighboring token contributes. That is why “bank” can start from the same base token embedding in “river bank” and “bank account,” but end up with different contextual representations. Attention is one of the key mechanisms that pulls those meanings apart.
If you know another good article or video that explains attention intuitively, feel free to add it in a GitHub Issue, and I am happy to update this list and share it.
Questions, corrections, or follow-up ideas are welcome on GitHub Issues.